

本文又((上一篇是《数字:「兆」与万位分隔符》。))是一篇从 Telegram 的投票评语里面引申出来博文。不知不觉发现这一话题写了很长,就索性再添上一些写进这里。我们不争论我们是否「应该」在中文里面用弯引号云云。如果没有硬性规定,按个人偏好就好。
首先,不同于大部分中文/全角标点,Unicode 里面有一些常用的中文标点是和西文中同样作用的标点共享相同的码位的:
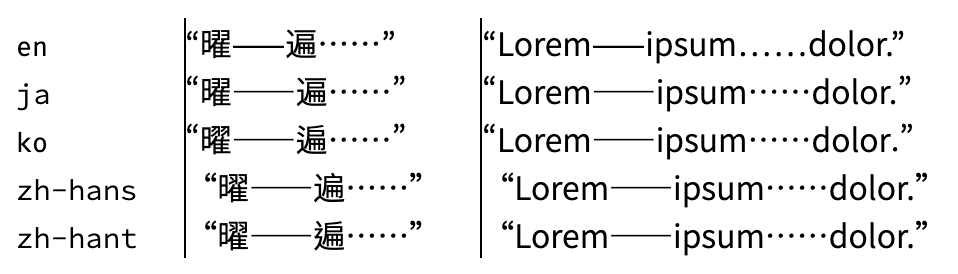
- “”
弯引号,在部分西文排版里面同样适用。中文里各占一个汉字宽((在正确渲染的情况下,本站使用了比例东亚标点和假名。故这里的标点都会只占字形的度量宽度,而不是设计宽度。))。 - •
间隔号,同上。 - …
省略号,同上。中文里占一个汉字宽,且居中。与西文不同的是,中文省略号通常打六个点。 - ——
破折号,表现为两个 em dash。西文排版中常使用一个 em dash,置于 x-height 中央。中文里面破折号居中,连打两个中间不应断开。或是直接使用更长的 2-em dash(⸺,U+2E3A)
关于破折号占用码位的历史遗留问题及混乱的现状,参见 The Type 的这篇文章。

这些标点在 Unicode 上面都是使用的同样的码位。Unicode(大致)的编码标准是「只编码字符(character)、不编码字形(glyph),除非有其他编码区分了两个字符」((当然例外是数不胜数的。))。
至于计算机展示给我们的究竟是中文的版本还是西文的版本,简单来说就是:看字体和渲染引擎。
理想状态下,在多语言混排中显示正确的标点字形需要内容提供者,渲染引擎和字体一起合作达成,并且需要用户为不同的语言文字安排使用各自适当的字体。
内容提供者
正如「信息安全最薄弱的环节是人」一样,排版质量中最重要的环节也是人。大多数足够复杂的排版系统都需要用户来为文章内容标记正确的语言,以适用适当的排版规则。有些时候像中文和英文这类较容易区分的语言,编辑软件可能会自动为内容做出区分,但像繁简中文这样更加难以区分的文种来说,自动标记语言终归是不可靠的。
因此,内容提供者需要给文字标注正确的语言。对于简单的文字处理环境,像纯文本编辑器或者聊天软件的输入框,因为设计原因,这些情况中软件在制作时通常不会考虑复杂的排版需求,而去依赖操作系统内置的文字组版引擎,更有甚者直接使用单一的字体进行文字的罗列。依赖操作系统的那些软件通常会使用软件设定语言——或者操作系统语言——作为适用排版规则的语言。而那些简单罗列字体字形的情况,就更加无可救药了。(作为一个半路出家的游戏汉化志愿者,一些游戏的文字渲染引擎都是以欧洲语言为中心设计的。排版引擎强烈依赖一个字符只有一种形状和不遇到空格不换行这两个规则,以至于直接塞进阿拉伯文字和中日泰文字基本上会得到一个不可用的结果。)因此这些情况里面在源头上面就已经做不到多规则的区分了。
其他较为复杂的排版工具,例如 Microsoft Word、一众 Adobe 软件,TeX 系列,甚至 HTML 5 搭配现代浏览器都可以对文字标注语言提示。
-
Microsoft Word
选中要标记的文字,在窗口的左下角会看到一个语言名字,双击这行字即可进行修改。在 Word 里面修改了文字的标记语言后同时也会适用对应语言的拼写和语法检查。 -
Adobe 软件
文本的语言设定通常在「文字」设定窗格的最下面。在一些软件里面需要在偏好设定里面启用东亚/印度文字选项。InDesign 中甚至有为不同语言提供不同的「书写器」选项以使用各种复杂且迥异的排版规则。(不过熟悉 InDesign 的人们也都大概熟悉这里面的内容了吧) -
TeX 系列
TeX 中的多语言排版通常是通过引用扩展包实现的。Babel 包提供了对于中文在内的大部分语言提供了支持,不过只有对欧洲语言的支持较为完整。其他一些中亚语言也有自己的语言支持包。中文常用 XeTeX 配套使用 xeCJK,日文甚至有它们专用的 TeX 变种:(u)pTeX。 -
HTML 5
网页上的语言标注就相对直观一些,直接在需要标注的节点上添加lang属性,属性值设置为语言的代号即可。
渲染引擎
渲染引擎层面上对于多语言字形处理大致分为两类:
仅实现 OpenType locl 功能支持
实现 locl 功能的支持在现代浏览器排版引擎中是比较常见的做法。经过一些测试,八款软件中有四款实现了 locl 功能支持,并允许用户标记文本的语言。
支持的程序:
- 浏览器
- Google Chrome
- Firefox
- LibreOffice Writer
- XeLaTeX
不支持的程序:
-
Microsoft Word (macOS)
语言设定选项没有影响字体 -
Apple Pages、macOS TextEdit
没有文本语言设定选项,但可以使用高级排版选项来手动逐个选择字体内包含的替代字形。 -
Safari
语言设定选项没有影响字体;Safari 12 起浏览器不再读取用户安装在系统里的字体
虽然上面讲到的这些排版工具中都是针对富文本(这里特指同时使用多款字体)编辑的,很多情况下选用多款字体适应不同文种是更普遍的选择,但是在支持 locl 功能的情况下直接使用单一字体也不失为一种简单方便的方式。
实现一套自有排版规则
这一做法常见于较为专业的排版软件中。有些足够复杂的排版引擎可以通过各种微调来直接使字形展现出需要的形态而无需字体的支持、抑或是能够为不同的情况自动选用不同的字体,因此单一字体对双文种的支持在这些情况下并不是必要的。
相比于 Microsoft Word 直截了当的在样式设定上为「亚洲文字」和「西方文字」预留了两个不同的字体选项,InDesign 则在「复合字体」之外为中文配备了与默认西文不同的「CJK 书写器」,用来适配包括标点符号在内的中文与西文迥然不同的文字结构和排版习惯。适用于 XeTeX 的 xeCJK 则采用了 TeX 自有习惯的 ASCII Smart Punctuation 式标点((例如开关双引号写作 ``''、连接号写作 --- 等))或是手动添加开关的方式来区分中西文共用码位标点((《xeCJK:增加选项处理引号的样式》,CTeX-org/ctex-kit GitHub Issue))。
字体
字体方面,目前现状下的最佳做法自然是尽可能使用不同的字体来排版不同的文种。这不仅对于现在大多数商用中文字体来说是几乎必须的,并且也可以设计人员抛开中文字体附带英文字形的束缚,找到更加搭配的组合。
不过这里还是想讲一下 OpenType 中的 locl 功能在中文字体和中英混排中的作用。locl 功能允许一款字体根据显示内容的语言和区域习惯来为同样的字符展示不同的字形。目前我所能发现的利用 locl 功能为中西文展示不同标点字形的只有 Adobe 设计的两款炫技(?)字族:思源字体和貂明朝((这两款字都包括了一些 Adobe 在现代 OpenType 应用在东亚字体的技术上的前沿探索:前者包括 Mega/Ultra TTC 共享字形;后者包括东亚字体内加入西文意大利体字形等。))。个人还是十分希望越来越多的中文字体支持使用 locl 功能来适配中西文标点的,毕竟一整套拉丁字母、数字、标点都画了,也不差五六个。更何况几乎就是拿画好的标点调整一下位置和大小而已。
相比于重绘标点,locl 功能更常用于——也是它原始设计的目的——为不同语言和区域展示当地的规范字形。除去刚刚提到的思源字体外,比较技术流的 GlyphWiki 生成字体(注意不是花園明朝),以及简中字体大厂方正的《兰亭黑 Pro》也都有使用 locl 功能来按需展示不同字形。

locl 功能启用「國字標準字體」字形,Linkzero Tsang。(虽然这个标准字型槽点也很多就是了)这一功能除用于东亚以汉字为中心的字体外之外,还常用于保加利亚语、塞尔维亚语中一些西里尔字符的规范写法。虽然同是使用西里尔字母,保加利亚和塞尔维亚由于文字设计和排印在历史发展上的不同,和俄罗斯相同文字的字形产生了区别。俄罗斯的印刷体字母更加倾向于大小写同形,而保赛的字母更加倾向于手写形态。《Cyrillic script variations and the importance of localisation》这篇文章详细介绍了几个国家之间字形的区别。

纵观一次中英文混排走过来的这一路历程,要完成一个「看起来没有大问题」的中英混排需要很多方面通力合作。时至今日,许多用户仍旧放任错误的标点在纸面/画面上。在排版软件和字体变得更加「智能」,逐渐开始自动的为用户提供近乎「傻瓜式」的更高质量排版的同时,更重要的是要教育用户,让他们明白什么样的排版才是「没有问题」的。尤其是在文书处理、平面设计软件门槛大幅降低的今天就更显得重要了。好的用户教育能够提高用户的审美,也能人用户自己做出更好的选择:不仅是对于中英混排,也包括避免使用那些连中文标点符号的位置还都摆放不对的字体((微软雅黑,说的就是你。Nobel Scarlet 有生之年还会发布么?))。这也从一个侧面影射出中文数字排版整个生态和普及还有很长的一段路要走。
发表回复