
文字化け、それは一昔前のパソコンにおいて情報交換でよく起こる不具合である。近年になってからは Unicode(だいたい UTF-8)がネット上の文字コードの事実上の標準になっており、意図しないで発生する文字化けはほとんどみられなくなった。今では、よくみられる文字化けはほぼ創作でホラー要素、謎解き、あるいは隠しメッセージとして登場している。その中に、最もよく使われている文字化けの種類は「Shift-JiS / UTF-8」による文字化けで、いわゆる「繝繧」とか糸へんの漢字がいっぱい入ってるのやつ。この記事は、「Shift-JiS / UTF-8」による文字化けを既存ツールよりはもうちょっと解読できる方法を解説します。
どれくらい解読できる?
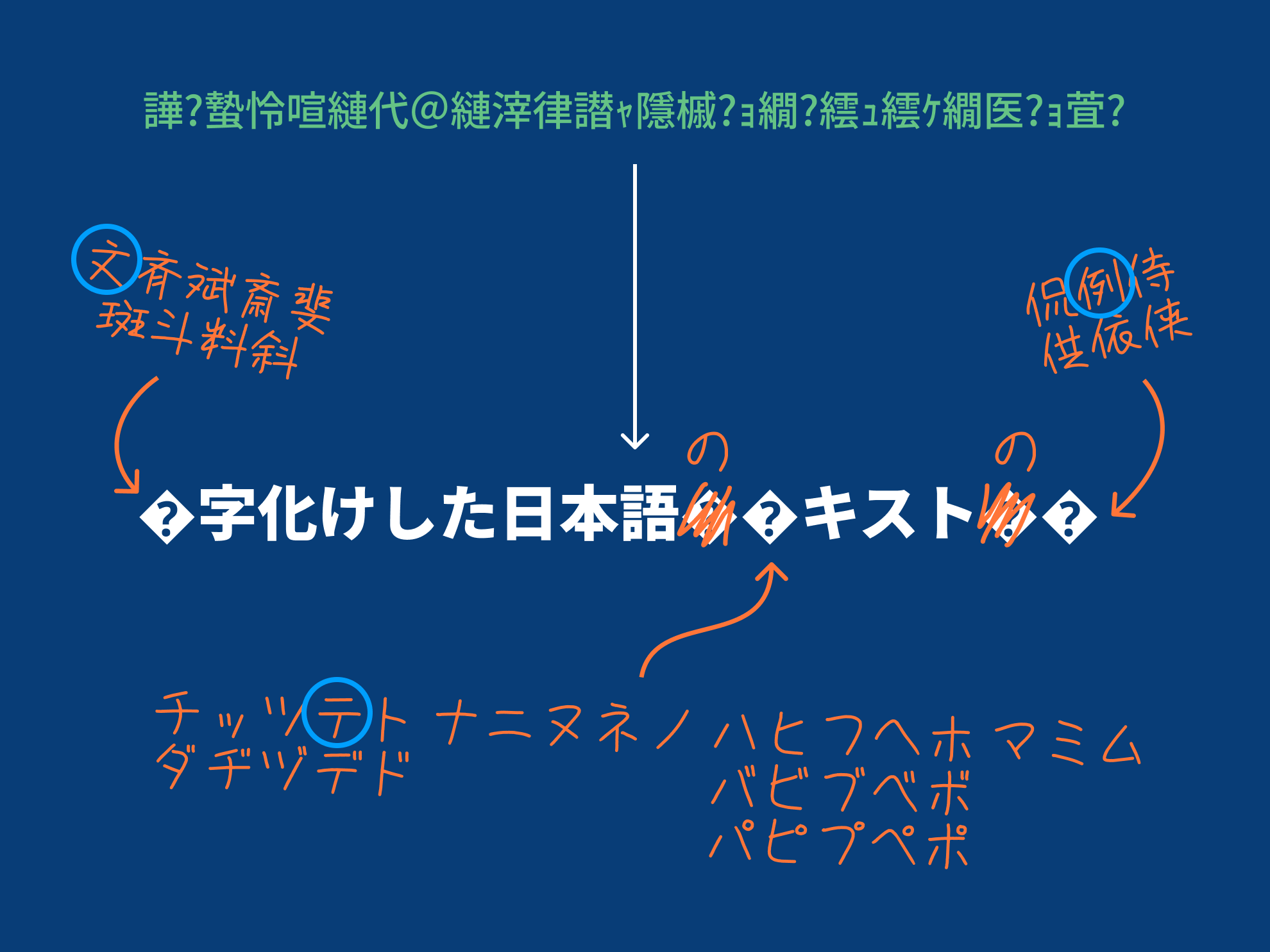
まず実際の解読例を見てみましょう。
| 元の文章 | 文字化けした日本語のテキストの例 |
| 化けた文字列 | 譁�蟄怜喧縺代@縺滓律譛ャ隱槭�ョ繝�繧ュ繧ケ繝医�ョ萓� |
| 既存のツールで解読 | �字化けした日本語���キスト��� |
| 今回のツールで解読 (JIS 第一水準漢字限定) | (文斉斌斎斐斑斗料斜)字化けした日本語(の)(ダチヂッツヅテデトドナニヌネノハバパヒビピフブプヘベペホボポマミム)キスト(の)(侃例侍供依侠) |
この例の通り、既存のツールで解読した「?」の部分に入りそうな文字の候補を提示してくれるのが今回のツールです。では、いったいどうやって候補を検出できるのかを解説していこう。
文字コードの前提知識
細かい仕組みに踏み入る前に、まずは今回扱う2種類の文字コード、Shift-JIS と UTF-8 の構造を少し見てみよう。
Shift-JIS は相対的に単純で、一文字は1バイトもしくは2バイトで構成して、それぞれで使える値の範囲が限られている。次の表の通り、1ビットは必ず 0x00–0x1F 0x20–0x27 0xA1–0xDF のどれかで、2バイトの場合は、1バイト目は 0x81–0x9F 0xE0–0xFC で、2バイト目は 0x40–0x9E 0x9F–0xFC に入ることになる。
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
対して、UTF-8 が対応する範囲がかなり広いので、符号化の体系もより複雑になっている。U+0000 から U+10FFFF までの約 111 万の符号位置を表す必要があるため、UTF-8 が使用するバイト幅が1バイトから4バイトまでになる。
| 符号位置の対応範囲 | 二進数表記 | UTF-8 符号化した二進数表記 | |||
|---|---|---|---|---|---|
| U+0000–U+007F | 0gfe dcba | | |||
| U+0080–U+7FFF | 0000 0kji hgfe dcba | 110k jihg | | ||
| U+8000–U+FFFF | ponm lkji hgfe dcba | 1110 ponm | 10lk jihg | | |
| U+100000–U+10FFFF | 000u tsrq ponm lkji hgfe dcba | 1111 0uts | 10rq ponm | 10lk jihg | |
パターン的に、1バイトから4バイトの構成ではそれそれ先頭のビットは確定されている。
実際に解読する
Shift-JIS でエンコードされた文字列を UTF-8 でデコードすると、対応する文字が見つからない場合があり、それが文字化けの原因となる。先の例文を使って実際エンコードするとこうなります。
| 元の文章 | テ | キ | ス | ト | の | 例 | ||||||||||||
| UTF-8 でエンコード | E3 | 83 | 86 | E3 | 82 | AD | E3 | 82 | B9 | E3 | 83 | 88 | E3 | 81 | AE | E4 | BE | 8B |
| Shift-JIS でデコード | 繝 | � | 繧 | ュ | 繧 | ケ | 繝 | 医 | � | ョ | 萓 | � | ||||||
| 復元できるデータ | E3 | 83 | � | E3 | 82 | AD | E3 | 82 | B9 | E3 | 83 | 88 | E3 | � | AE | E4 | BE | � |
上の表の�の部分は、データを Shift-JIS として解読する時にデータに対応する文字が見つからないため、仮に置かれるプレースホルダーである。元データと照らし合わせると、「テ」「の」「例」に対応するデータの一部が復元できないことがわかる。このため、一般の文字化け解読ツールは「�キスト��」までしか解読できない。
ただし、この場合で失ったデータは1文字ごとに1バイトだけ、残った部分はまだ解読のヒントになれるはず。いくつかの仮定を立てて、この表をより細かく分けてみよう。
仮定その1:元データは有効な UTF-8 データ
| 元の文章 | テ | キ | ス | ト | の | 例 | ||||||||||||
| Unicode 二進数表記 | 0011000011000110 | 0011000010101101 | 0011000010111001 | 0011000011001000 | 0011000001101110 | 0100111110001011 | ||||||||||||
| UTF-8 二進数表記 | 11100011 | 10000011 | 10000110 | 11100011 | 10000010 | 10101101 | 11100011 | 10000010 | 10111001 | 11100011 | 10000011 | 10001000 | 11100011 | 10000001 | 10101110 | 11100100 | 10111110 | 10001011 |
| UTF-8 十六進数表記 | E3 | 83 | 86 | E3 | 82 | AD | E3 | 82 | B9 | E3 | 83 | 88 | E3 | 81 | AE | E4 | BE | 8B |
| Shift-JIS でデコード | 繝 | � | 繧 | ュ | 繧 | ケ | 繝 | 医 | � | ョ | 萓 | � | ||||||
| 復元できるデータ | E3 | 83 | � | E3 | 82 | AD | E3 | 82 | B9 | E3 | 83 | 88 | E3 | � | AE | E4 | BE | � |
| 復元データ二進数表記 | 11100011 | 10000011 | � | 11100011 | 10000010 | 10101101 | 11100011 | 10000010 | 10111001 | 11100011 | 10000011 | 10001000 | 11100011 | � | 10101110 | 11100100 | 10111110 | � |
| 復元 Unicode 二進数表記 | 0011000011______ | 0011000010101101 | 0011000010111001 | 0011000011001000 | 0011______101110 | 0100111110______ | ||||||||||||
タイトルに書いた通り、当然元データは UTF-8 でなかったり、改変したりすると、そもそも大前提が成り立たない。この仮定のもとに、復元できない部分を UTF-8 の先頭ビット規則に当てはまると、実際に失われたデータはこの場合 8 ビットずつではなく 6 ビットずつになる。
1 ビット、つまり二進数の一桁は 0 か 1 の二通りで構成するから、6 ビットの組み合わせは 26 = 64 通りになる。これで無限にある可能性から一文字分 64 個の候補に絞られます。
この仮定で絞られた候補はこちら:
一文字目・二進数の 0011000011______ に当てはまる Unicode 文字:
ダチヂッツヅテデトドナニヌネノハバパヒビピフブプヘベペホボポマミムメモャヤュユョヨラリルレロヮワヰヱヲンヴヵヶヷヸヹヺ・ーヽヾヿ
二文字目・二進数の 0011______101110 に当てはまる Unicode 文字:
〮のギヮㄮㅮㆮ㈮㉮㊮㋮㌮㍮㎮㏮㐮㑮㒮㓮㔮㕮㖮㗮㘮㙮㚮㛮㜮㝮㞮㟮㠮㡮㢮㣮㤮㥮㦮㧮㨮㩮㪮㫮㬮㭮㮮㯮㰮㱮㲮㳮㴮㵮㶮㷮㸮㹮㺮㻮㼮㽮㾮㿮
三文字目・二進数の 0100111110______ に当てはまる Unicode 文字:
侀侁侂侃侄侅來侇侈侉侊例侌侍侎侏侐侑侒侓侔侕侖侗侘侙侚供侜依侞侟侠価侢侣侤侥侦侧侨侩侪侫侬侭侮侯侰侱侲侳侴侵侶侷侸侹侺侻侼侽侾便
つまり、今のところの解読予想はこうである
仮定その2:元の文字列は日本語である
さっきの仮定で 64 個の候補に絞られたが、並べるとまだ多すぎる気がする。ここで2つ目の仮定の登場です。原理的に UTF-8 でエンコードされたデータが Shift-JIS でデコードするだけだから、どんな言語でもできるが、「そもそも日本語じゃないと Shift-JIS で化ける必要なくない」と思っちゃうから、ここで原文が日本語であることを仮定する。
上のリストに「ㅮ」や「侦」など日本語じゃほぼ絶対使わない文字が散見するが、文字単位で十分な言語判定はできないから、ここで大まかに Shift-JIS に符号化できる文字のみを「日本語」とします。
この条件で絞られた候補は以下のとおりである。かなり少なくなったね。
仮定その3:化け戻すとデータはロストしなければならない
タイトルはちょっと回りくどいが、まず以下の例を見てみよう。一文字目の候補の「ム」と「メ」の2文字に注目して、それぞれが当てはまる場合再び文字化けをする時の結果を求めよう。
「ム」の場合
- 予想の原文:ムキスト…
- UTF-8 でエンコード:
E3 83 A0 E3 82 AD… - Shift-JIS でデコード:繝�繧ュ…
- 解読したい文字列:繝�繧ュ…
「メ」の場合
- 予想の原文:メキスト…
- UTF-8 でエンコード:
E3 83 A1 E3 82 AD… - Shift-JIS でデコード:繝。繧ュ…
- 解読したい文字列:繝�繧ュ…
一文字目に「ム」を代入して予想の原文を化け直すと最初から解読したい文字列に一致する結果が得られるが、「メ」の場合は化け直す文字列に�が含まれていない。つまり、背理法 (?)によって「メ」は一文字目ではないことが証明できる。この方法で全ての候補を化け直してチェックすると、候補をさらに絞られます。
これで5文字目が「の」であることを確定できました。
仮定その4:難しい漢字は使わない(任意)
さっきの候補はすでにかなり絞られたが、中にはまだ「侈」や「侊」など普通じゃ読めない漢字がかなり残っている。解読したい文字列の出自にもよるが、難読漢字は出ない場合は多いだろうと仮定する。ここは上の候補の中にある漢字を JIS 第一水準漢字に絞ると、こうしてさらに候補を減らせる。
当然、自信があれば常用漢字や教育漢字などの文字集合に絞るのもありです。
補足:1バイトと2バイト⸺デコーダ仕様の違い
最後に補足したいのは、文字化けはツール(デコーダ)の仕様によって結果はかならず同じではないこと。私はいろんな文字化けツールを試している中、一つ面白いことが気付いた。それは、ツールによっては同じ文章でも、文字化けにすると違う結果が出て、それぞれデコードできないデータの処理方法が違うことである。ここでデコーダをその仕様で「1バイト類」と「2バイト類」に分ける。
「1バイト類」のデコーダは解読できないデータを見つけたら、1バイト飛ばして次から解読するものである。例えば、「E3 83 86 E3 82 AD」をデコードするときはこういう風になる:
E3 ← 2バイト文字の第1バイト、次のバイトを見る
E3 83 ← 繝
繝 86 ← 2バイト文字の第1バイト、次のバイトを見る
繝 86 E3 ← 対応する文字がない、次のバイトから再開
繝� E3 ← 2バイト文字の第1バイト、次のバイトを見る
繝� E3 82 ← 繧
繝�繧 AD ← ュ
繝�繧ュ ← 結果
対して、「2バイト類」のデコーダは解読できないデータを見つけたら、解読できない部分をまとめて飛ばすものである。例えば、同じく「E3 83 86 E3 82 AD」をデコードするときはこういう風になる:
E3 ← 2バイト文字の第1バイト、次のバイトを見る
E3 83 ← 繝
繝 86 ← 2バイト文字の第1バイト、次のバイトを見る
繝 86 E3 ← 対応する文字がない、まとめて飛ばす
繝� 82 ← 2バイト文字の第1バイト、次のバイトを見る
繝� 82 AD ← く
繝�く ← 結果
このため、デコーダによっては、�が1バイトを意味する時があるし、2バイトを意味する時もある。冒頭にあるツールで「?」は1バイトを意味するため、�を1バイトや2バイトに変換するボタンを用意した。片方が解読できなかったら、もう一方も試してみよう。
これからさらに絞りたいなら、たぶん文脈で頑張るしかないかなと思う。この方法で、最初の無限にある選択肢からかなり限られたオプションに絞られて、文脈で当てる難易度も結構下げたと思う。
もしこの先にまたどこかで文字化けを解読したい時があったら、この記事・ツールが役に立つことができたらとても嬉しいです。ではまた。
コメントを残す