

Similar to the last post I did on a mobile game, this time again is another online battle game from Baton and QuizKnock — Tonguess (Android, iOS). In short, Tonguess is a word version of Bulls and Cows, once played by members of QuizKnock in a video.
How to play
Rules of Tonguess is simple: there are 2 players in a game, each player first comes out with a heterogram (word with no repeated letters) word in the dictionary of the game app. Length of the word to guess is decided prior to the game – either 3 letters or 4. Then they shall take turn to make guesses of the word of their opponent. Once a player makes a guess, the app will tell you how close you are to the answer. It will tell you 2 numbers:
- Touch (a.k.a. cow, eat, B) is the number of letters you got correct but in the wrong place.
- Get (a.k.a. bull, bite, A) is the number of letters you got correct and also in the right place.
Despite the word you choose at the beginning must be in the dictionary, you can use any combination of letters
Once a player guessed the word correctly in less rounds than their opponent, the game is won by the player. Similarly, it will be a draw round if both players got the word of each other in the same number of guesses.

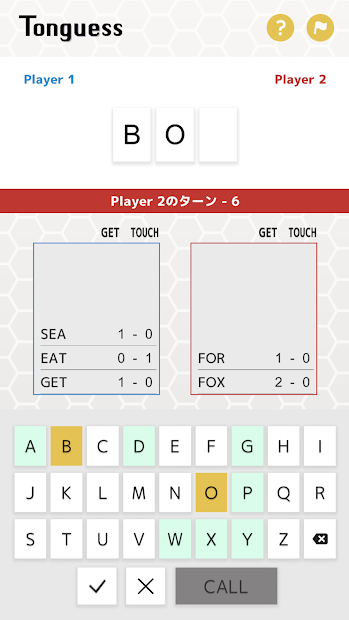
Solving the game
The dictionary
Dictionary plays a great part throughout the gameplay of Tonguess. The custom in-game keyboard used in both setting and guessing words provides strong visual hints on what words are in the dictionary. In the game settings menu in the home screen, there is even an option for you to go through all words in its dictionary and redirect you to a Google search on tap.

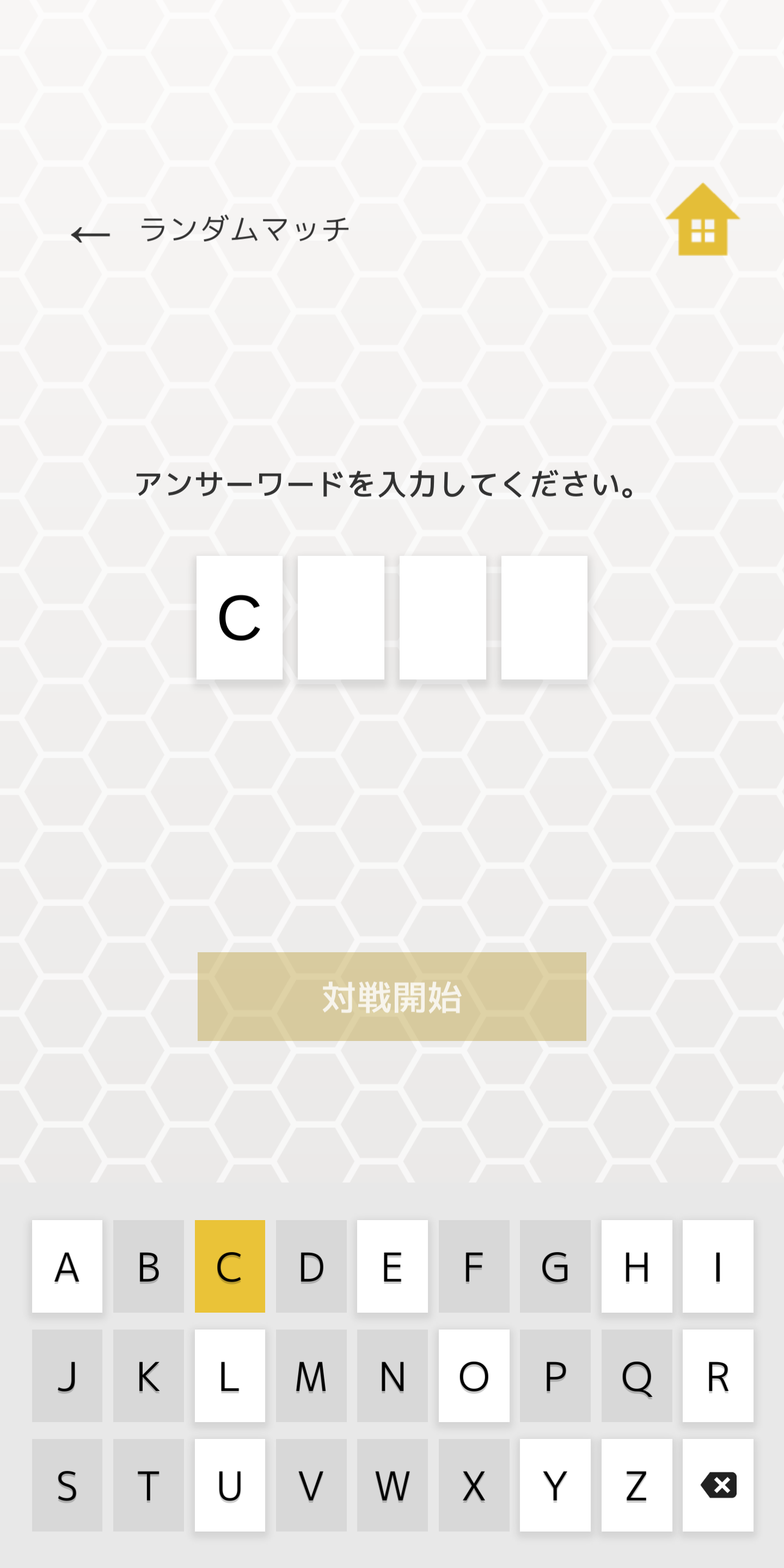



Hence, effectively every player can get hold of the dictionary and know whether a word is valid or not. What’s even better is that, after unzip the Android APK file, somewhere hidden in a binary file in the assets folder is the entire word list. That has later saved me a lot of time cracking the game.
Gameplay
As introduced previously, the strategy is pretty static. Apart from the answer to guess, nothing really changes from game to game, all other information like the word size and the dictionary are known prior to the games. It’s completely possible to build a single decision tree out of what we already have and use it across all future games.
While I was reading on relevant materials online on solving similar games, all of them were solving the number version of the game, which has the same range and domain, i.e. what you can guess is exactly what they can put as their answers. In this case, the path exploration process is more “symmetrical”, it needs to focus more on the number patterns in order to narrow down the candidates. Also, in this case, the exact number combination you start with doesn’t really matter, as wherever you start with a certain pattern, you can explore with the same strategy.
However, in Tonguess, the range and domain is not the same. The domain – what you can guess – is the entire n letter combination without replacement, {26 \choose n}; while the range – what you can put as an answer – is only limited to the number of entries in the dictionary.
Running through the binary file I found in the Tonguess APK with all dictionary words with a few Linux commands, I then got 2 files: one for those in 3 letters, and the other for 4 letters. They each had 711 words and 1799 words respectively, which is really not a lot comparing to the domain.
In this way, it probably makes more sense to use other strategies to build the decision tree statistically.
Building the decision tree
At the beginning, I was thinking of methods like MCTS, but due to the fact that back then my access to a decent computing power (i.e. my laptop) is greatly limited, I did not have the luxury to do trial-and-error with a Monte Carlo method that might not work after all.
Instead, I turned to other more brute force-y methods of building the tree. My first (and by far the only) idea is inspired by binary search. For every guess sent of n letters, there will be a maximum of 1+2+\cdots+n+(n+1) possible feedbacks. Despite the nature of the game that more candidates are inclined to appear in those with less confirmed letters, with some even max out at 1, we want the distribution of candidates to be as even as possible for each and every guess. With my bare minimum knowledge from my Data Processing 101 course, I used standard deviation of branches as the heuristic function to decide which branch to explore.
The algorithm is rather straight forward:
Treat every game state as a tree node, with the current candidate words for answers.
for each node
go through every possible guess
find the one with the best heuristic value
record down the guess
then build a node for each feedback to explore later
repeat until a tree node has 0 or 1 candidate word.
One small detail to note: when there are multiple guesses share the same heuristic value, we want to choose the one that has a n-get-0-touch, as that would potentially save us one guess to win the game. The reason why we are looking at the actual candidate rather than checking if the guess is in the dictionary is that, sometimes a guess may be in the dictionary, but it could have been eliminated way up in the tree.
Coding it out
After I had the dictionary sorted out, I started write functions and scripts to help generate data I need along the way.
Before we get into the code, there are some terminologies I want to clarify here to better navigate you thorough the way.
- candidates are the words that the opponent that could possibly put as their answer to the best of our knowledge at the current state;
- a guess is a word we guess, or could guess in the game;
- an outcome, or a feedback, is two numbers that we get after making a guess, could be formatted as x-get-y-touch, x – y, or (x, y);
- the word length is the number of letters in the word we are guessing, i.e., either 3 or 4, usually denoted with n;
- the dictionary size is the number of words in the dictionary of a specific word length, denoted with w_n.
The first building block is cal_outcome(guess, answer) -> Tuple[int, int]. As the name suggests, calculate the outcome from a guess and an answer. Apart from a few little quirks here and there, this is a pretty trivial function.
Coming after that, I built a lookup table for candidates grouped by outcomes for every guess at the initial state. This too was simple, but leaving all guesses and candidates in their string form has already taken me a few hundred MB just for 3 letter words in the plain Python Pickle syntax. I then tried to store the guesses as their indexes (in lexicographical order), and the grouping as a w-bit integer instead. (If a certain word is in that group, the corresponding bit is set to 1.)
With those little tricks, the mapping size has been reduced to 8 MB and 603 MB respectively. I have also used multiprocessing to speed up process.
Following that, I now can start building the decision tree. I almost completely followed the pseudo code laied out before, except using an external library to help counting number of 1s in a binary integer, and multiprocessing to parallelize the heuristic calcuation.
I couldn’t be bothered to think of ways to trim edges by looking into the nature of the gameplay strategies, my laptop has waaaay more time to compute than I have to put my code on it.
The time complexity of this one is about \mathcal{O}({26 \choose n} \cdot n^2 \log w_n ). Sounds like a lot, but we’re not working on a competitive programming problem anyway. Looking at the CPU usage history graph, the 3-letter tree took a bit over 20 minutes, and the 4 letter one took about 4.5 hours.
Now we have the trees. Just one script to translate the numbers back to words, and another REPL-like script to move down the tree, it is finally ready to be played with.
What about entropy?
While reading on some more materials on this, I found out that entropy could be a better heuristic than standard deviation in this specifically setup with an inclined distribution.
I then duplicated my old script, replaced the heuristic function with entropy, and then a script to compare the two types of trees.
Surprisingly, with the help of numpy, the entropy trees were built almost twice as fast as the standard deviation one. The results of comparison shows that the 2 methods are basically on the same track, with the entropy one finishes a few dozen words earlier than the other.
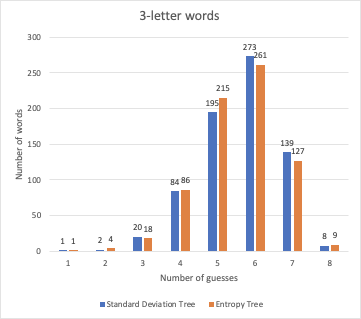
Chart for 3-letter words 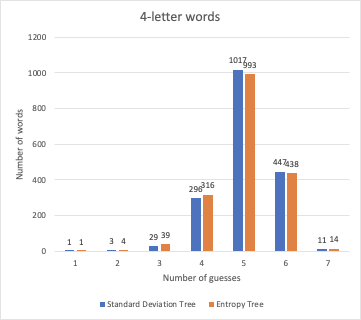
Chart for 4-letter words
The decision tree

Taking a look at the tree we’ve got here, it does confirm with some of the strategies I find online to solve Tonguess.
- Iterating through all possibilities n letters at a time when you have n-1 letters confirmed.1
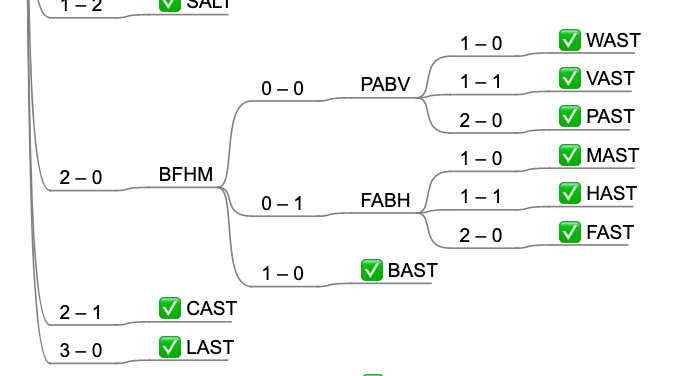
*AST candidates.- Start a game with a word containing O, A or E.2 The generated tree started with the word OAT and TARE.
A web solver
Once we got the tree, which isn’t any big at all, we can use some JavaScript and a static web page to make a Tonguess solver.
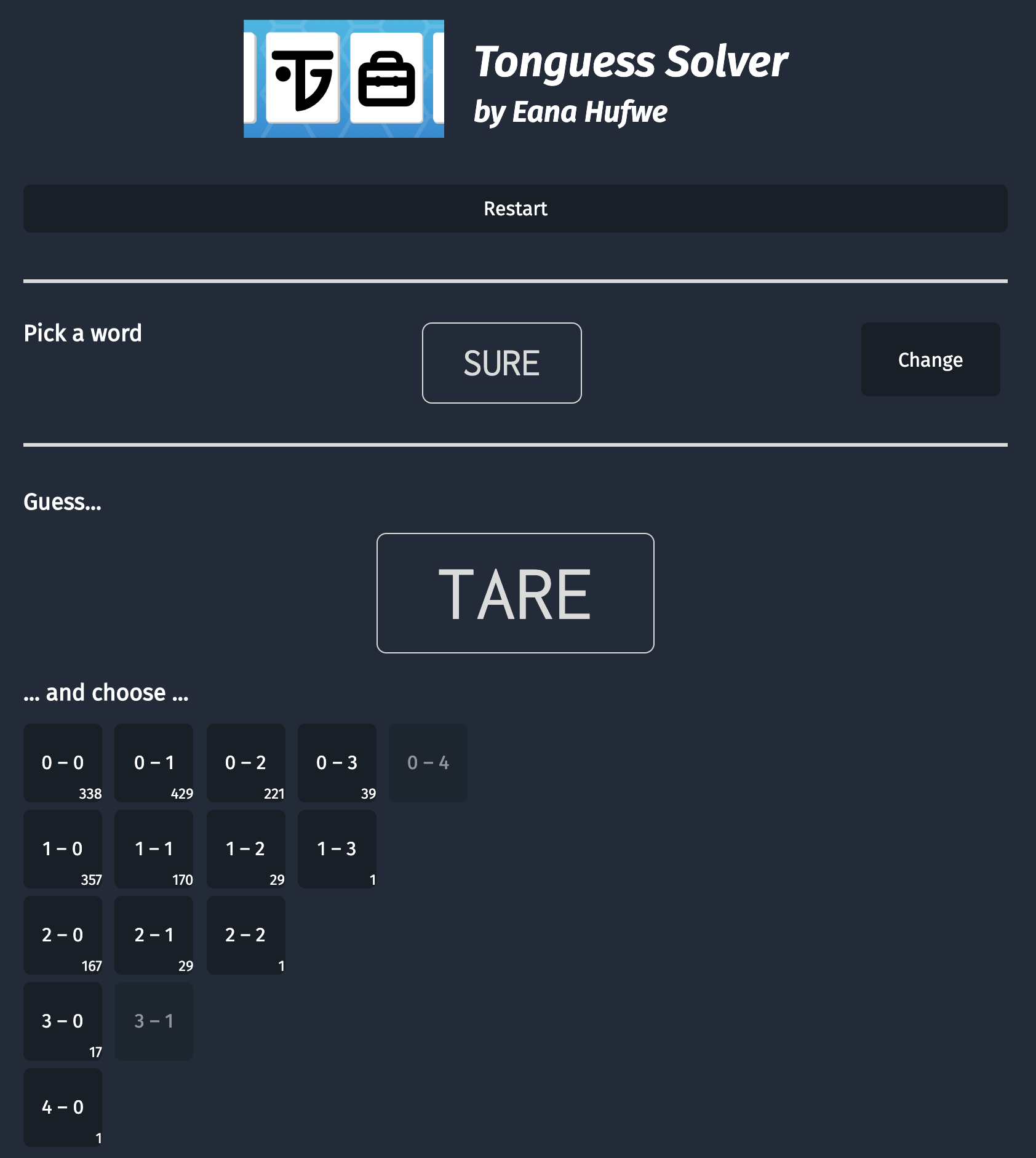
The solver page and all source code mentioned above are available on GitHub.
Further improvements
In the future, this strategy of tree building can be further improved. Some of these potential improvements including:
- Edge trimming strategies
This could significantly improve the efficiency of the current tree building algorithm. For instance, in states where multiple letters are eliminated from the candidates, all guesses including these letters could potentially be reduced into a few due to the identical result they produce. - Put more weight on more common words
The current strategy assumes all the words appear in the same frequency, which might not be the case for human. Incorporating the frequency may increase the chance of winning when playing against real players. - Explore more options
There are potentially more info that we can exploit, or other strategies that could solve this game even faster.
Traffic analysis
As I explore further into the mechanism of the game, I realised that Tonguess – despite also being a game developed under the QuizKnock brand in the same genre – is designed with quite some difference from their first game Genkai Shiritori Mobile (GSM).
- Tonguess keeps all the valid words locally, potentially due to the limited nature of dictionary, while GSM requires player to send the word up to their server to verify.
- GSM has a global ranking for scores and words used and resets every month. Tonguess has no hint of any ranking at all, except a “rating” of your own which you can find in the app settings, and the rating of the opponent only available during the game.
Taking a chance, I fired up a packet inspector on my phone to capture the traffic.
As usual, those connected to Google servers, potentially for Play Services and IAPs, are HTTPS/TLS encrypted and not of our interest here. Yet the other connection, to connect for the actual gameplay, is not linked to Firebase anymore like GSM, but to a server claims to be gctok000.exitgames.com3, in an unusual port (TCP 4531). After some digging, it seems that this time they are using a game networking service called Photon Realtime. More importantly, the traffic is not encrypted, and that has enabled me to take a better look at what is going on behind the game.
The traffic
Photon Realtime uses a custom protocol on top of the classic TCP. Most of the traffic is ASCII data surrounded by binary components. I didn’t go too deep into decrypting those binary structure, but the ASCII payload itself is interesting enough for us.
When an opponent is first matched, the metadata of player is exchanged in a big JSON object, including:
- Player ID (UUID)
- Nickname
- Rating as a float number with a long chunk of decimal places not shown to the player
- Statistics
- Number of rounds won, lost and drew for 3-letter rounds
- And that for 4-letter rounds
- Complete history of all unique 3-letter words the player has played (responsible to show the number of unique words played and the recent word history),
- And that for 4-letter words.

It turns out, all these data are stored locally. For Android phones, they are URL encoded in one of the preference storage XMLs, and could be easily tampered with Root access. I guess, by storing the metadata of players locally, it could save a lot of server resources of the game maker, and thus reduce the operation cost. That could be why Tonguess comes with no global ranking compared to GSM.
After that, when the game actually starts, the game to guess was exchanged between players, again in plain text. This is actually very surprising to me. Despite that it could be a solution to avoid player missing the answer of their opponent once the connection is dropped, sending the answer in plain text enables players to cheat in the game in whatever way they like.

They can even just straight out call out the answer at the beginning and win the game straightaway. But given there is no global ranking in the game, only a rating number – only shown when playing against others and can be changed even more easily – there could really lack of a motivation for anyone to do so.
Traffic after that isn’t particularly interesting anymore, just commands to update and switch the timer, delivering guesses to and fro, and heartbeat packets to ensure both players are still around (which could be what the communication library doing instead of the game devs).
Overall speaking, the game design and engineering is roughly up to the standard it aims to be — intelligently triggering, but not too complicated for both developers and players. Interest of the game may drop over time, but doesn’t make it too hard for it to maintain playable for returning players.
- 英単語ヌメロン「Tonguess」攻略・コツなど — またりんの限界日記[↩]
- 【世界最速!!!】Tonguess攻略② — しゅぎもん[↩]
000can be any numbers from009to012[↩]
Leave a Reply